在科技投资的宏大叙事里,华尔街最擅长的就是为每一个微小的技术迭代包装出数千亿美元的“总体可寻址市场(TAM)”。在这一轮 AI 算力狂欢中,“光连接(Optical Interconnect)”无疑是被聚光灯打得最足的概念之一。从“算力爆发必带来光模块无处不在”到“CPO技术重塑数据中心”,激进的研报不断刺激着投资者的神经。
然而,剥开这些被精心包裹的幻象,回到最底层的服务器成本拆解(BOM)与物理工程现实,我们会发现一个被刻意忽略的真相:光连接概念正面临着严重的过度炒作。在 AI 硬件的权力版图中,它只是一个缺乏溢价资本的边缘角色。
一、 账本里的真相
AI 硬件的绝对核心只有 GPU 和 HBM 华尔街乐于展示光连接设备出货量的同比翻倍增长,但他们很少会让你看一眼一台标准 AI 服务器的真实成本构成。
以目前全球数据中心标配的 8 卡 NVIDIA H200 服务器为例,其整机建议零售价(MSRP)约为 $350,000。当我们把这张账单拆细,其价值链的真实垄断格局一目了然:
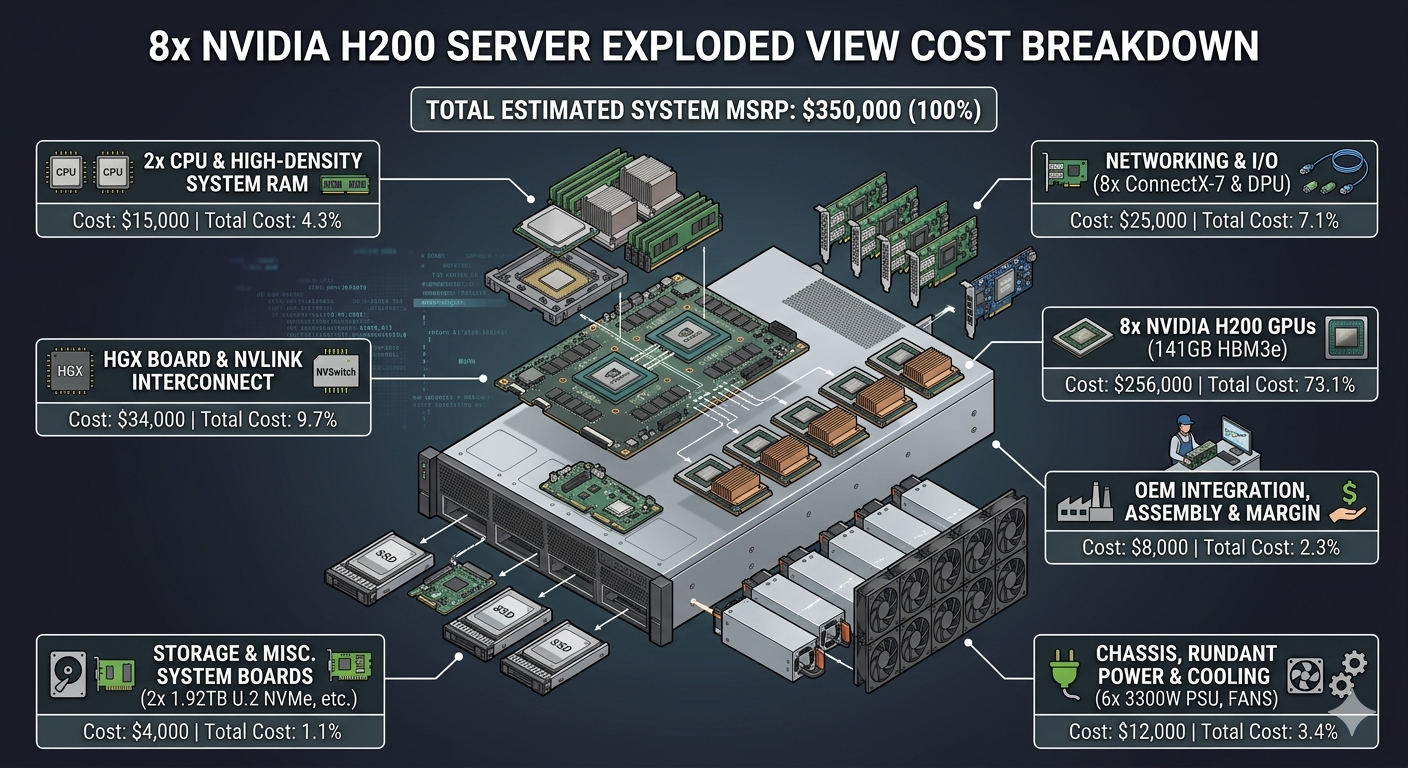
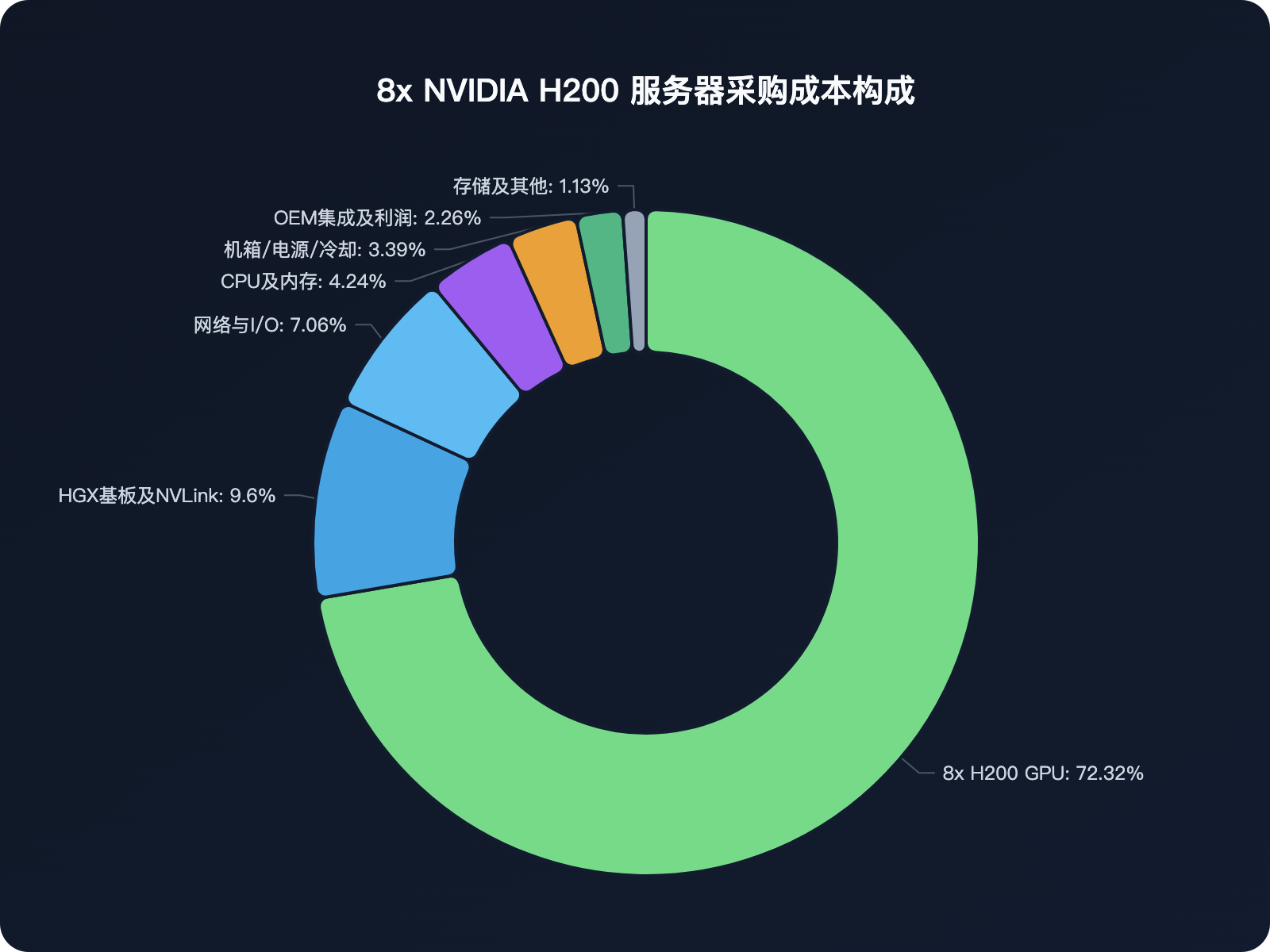
- 绝对核心:8 块配置了 141GB HBM3e 显存的 H200 GPU 核心采购成本高达 $256,000,直接吞噬了整机 70% 的资金。
- 边缘分润:包含了高速网卡、光通信接口在内的整个网络与 I/O 组件,在单机整机中的采购成本仅占 7%。
在 AI 硬件中,任何不能直接贡献算力(FLOPS)或显存带宽(HBM)的组件,都是外围设备。英伟达凭借核心芯片与 CUDA 生态卷走了全产业链近一半的纯利润,而光连接设备在整机中只是极其边缘的硬件,由于缺乏生态护城河,其价值根本不存在爆发的基础。
二、 机架内互联: 被高估的“全光”刚需
华尔街的叙事逻辑是线性外推:速度越快,就越需要光。但他们没有告诉你的是,在短距离互联中,铜连接已经取得巨大突破:
目前基于纯铜互联的 NVLink 6 已经能够实现单卡双工 3.6TB/s、机架级一二百 TB/s 的惊人带宽,至少在目前已经相当够用。
光通信听起来快,但它必须在传输时进行 2 次光电转换,这个过程会引入不可避免的物理延时,光电转换也有能耗、发热问题。铜连接工艺成熟、技术稳定、直接传电信号,近乎零延迟,性价比极高。
对于下游客户(如云服务商)而言,机架内通过现有的铜互联方案已经足够快、足够稳。这就像当年的 5G 概念和 IPv6 升级一样——技术指标固然完美,但在老的 4G 和 IPv4 依然够用且极其省钱的背景下,用户缺乏迫切的升级动力。
三、 集群光互连: 缺乏爆发逻辑
当然,不能否认光连接的价值。在超大集群的构建中,光连接具有铜缆无法替代的优势:
- 打破距离限制:当万卡、十万卡集群需要跨机柜、跨机房甚至跨建筑连接时,铜缆在超过 2-3 米后信号会发生剧烈的物理衰减。此时,必须通过光纤通信来突破距离限制。
- 但这不会造就价值爆发:光连接在多机柜集群中确实有刚性场景,但它无法改变其在整体数据中心资本开支(CapEx)中仅占个位数的边缘地位。更重要的,这类光通信设备缺乏像核心算力芯片那样的技术专利垄断和软件生态锁死,随着代工厂规模化量产与良率提升,其 ASP(平均售价)必然被下游客户持续压低。
总结
华尔街制造“光连接”的增长神话,过度炒作光连接概念。我们必须看清底层的硬核逻辑:AI 硬件的绝对重心始终在核心芯片(GPU)与高带宽显存(HBM)身上。光连接在 AI 硬件中必然有一席之地,但也仅仅是一席之地,不会成为下一个英伟达。
