- 一、 铁王座:CUDA 凭什么成为英伟达的护城河?
- 二、 只是致敬,并非抄袭:ROCm 与 CUDA 的底层异同
- 1. 硬件控制原理:高度一致
- 2. 软件生态构建:闭源黑盒 vs. 开源标准
- 三、 悖论:AI 正在摧毁毁 CUDA 的围墙?
- 1. 自动重写:生成式 AI 抹平了代码迁移成本
- 2. 降维打击:大一统中间件(Triton)的崛起
- 四、 反击:英伟达的防御与应对措施
- 1. 从“卖芯片”彻底转变为“卖数据中心系统”
- 2. 恐怖的“摩尔定律”速度压制(时间窗口战)
- 五、 展望:双雄逐鹿的终局走向
- 英伟达(NVIDIA):向系统级平台与云计算巨头演进
- AMD:在推理(Inference)与企业级市场迎来历史性爆发
- 总结:AI 没有毁灭英伟达,但 AI 会解放硬件市场
在硅谷的商业史上,很少有一家企业能像英伟达(NVIDIA)这样,凭借一套软件生态筑起数千亿美元的商业高墙。这堵墙的名字叫 CUDA。
长期以来,业界形成了一个牢不可破的共识:买英伟达是为了它的硬件,而留下来是因为它的软件。
然而,历史往往充满了反讽。随着由英伟达亲手引爆的生成式 AI 浪潮走向纵深,一个意想不到的“回旋镖”正加速飞回:AI 越强大,重写和迁移 CUDA 代码的门槛就越低。英伟达引领的 AI 革命,正在反向削弱它自己最引以为傲的软件护城河。
这是一场关于编译器、中间件、开源力量与人工智能自我进化的硬核博弈。
一、 铁王座:CUDA 凭什么成为英伟达的护城河?
要理解城墙是如何倒塌的,首先要明白它是如何建立的。
在 2006 年之前,GPU(图形处理器)只是单纯的游戏显卡。如果科学家想要用 GPU 运行数学矩阵运算,必须把数学公式伪装成“图形渲染指令”喂给显卡,编写过程极其痛苦。
2006 年,英伟达推出了 CUDA(统一计算设备架构)。它的核心贡献在于:允许程序员直接使用 C/C++ 语言来编写控制 GPU 的并行计算代码。
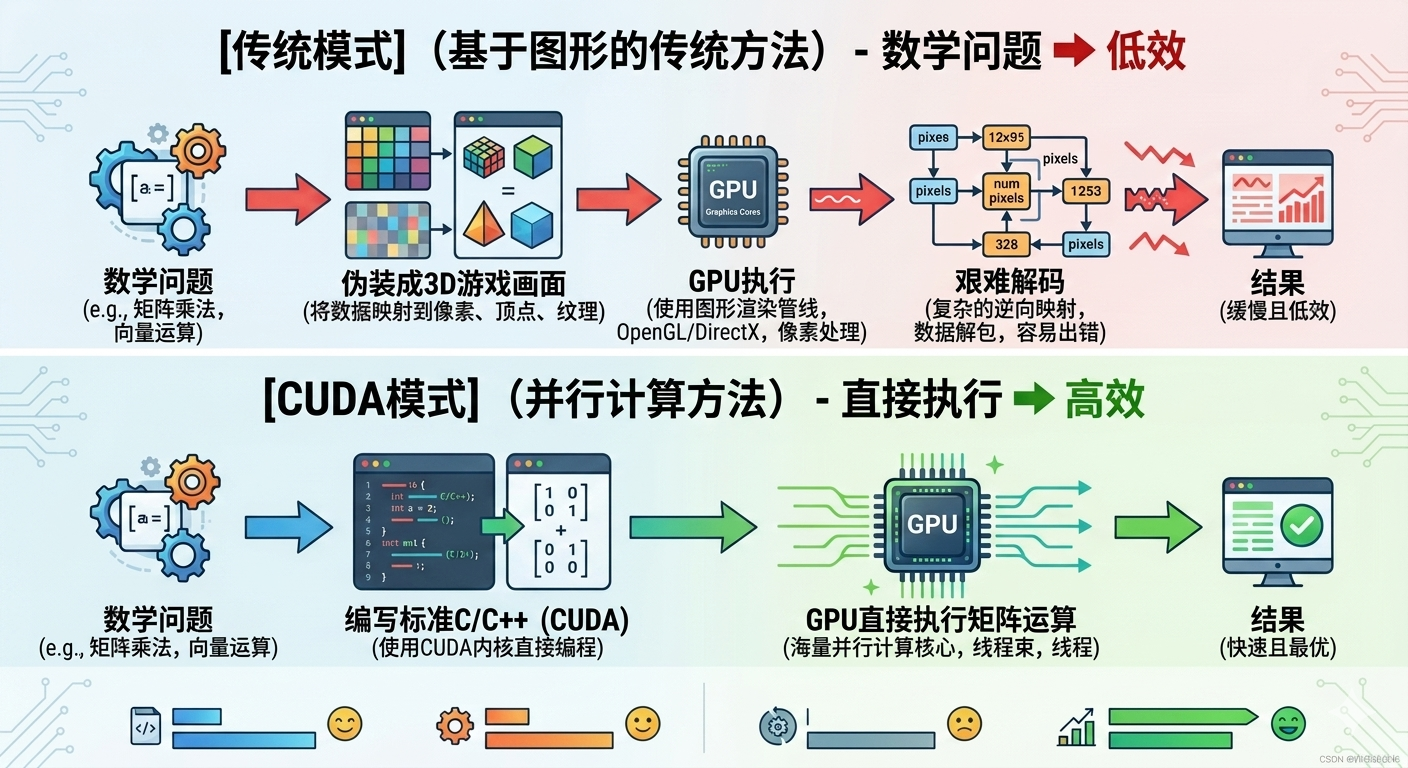
为了推广 CUDA,黄仁勋做出了一个在当时看来极其疯狂且亏损巨大的决定:强制让英伟达出厂的所有显卡(包括千元级的GeForce游戏显卡)都必须内置 CUDA 模块。事实证明老黄的这一决策极具远见!
这一决定为英伟达创造了一个价值数千亿的护城河,带来了两个决定性的商业结果:
- 人才基础绝对垄断:过去 18 年里,全球无数的高校学生、科研人员和独立开发者,只需用自己的游戏电脑就能零门槛学习 CUDA。当这批人毕业进入大模型公司或云巨头企业时,他们只会使用 CUDA。
- Day-0 生态锁死:全球几乎所有的 AI 开源论文、创新大模型(如 Transformer、Diffusion、Sora),在 GitHub 上发布的第一天,默认代码全部基于 CUDA 编写。
英伟达借此收起了超过 75% 的高昂硬件毛利,史称 “英伟达税”。企业想要更便宜的硬件?对不起,你离不开 CUDA。
天下苦英伟达久矣,苍天已死,ROCm当立!
二、 只是致敬,并非抄袭:ROCm 与 CUDA 的底层异同
为了打破英伟达的垄断,AMD 在 2016 年推出了开源的 ROCm(Radeon Open Compute platform)。从技术实现原理来看,两者的底层逻辑呈现出“异曲同工”,但在软件栈的构建思路上却“背道而驰”。
1. 硬件控制原理:高度一致
在最底层的芯片控制上,CUDA 和 ROCm 都基于 SIMT(单指令多线程) 架构。两者的核心概念在物理硬件上几乎是一一对应的:
- 英伟达的 Thread≈ AMD 的 Work-item
- 英伟达的 Warp(32线程)≈ AMD 的 Wavefront(波前,32/64线程)
- 英伟达的 Block(线程块)≈ AMD 的 Work-group
因此,无论是 CUDA 还是 ROCm,优化矩阵运算和控制显存缓存的数学逻辑在本质上是互通的。
2. 软件生态构建:闭源黑盒 vs. 开源标准
两者的真正差异在于编译器和代码的生成机制:
CUDA 的 NVCC 编译器:英伟达采用全自研且闭源的 NVCC。它将代码编译成一种私有的虚拟中间语言 PTX,再通过闭源驱动实时翻译成特定显卡的机器码。其内部的数学加速库(如 cuDNN、TensorRT)经过了 18 年的黑盒调优,外界无法窥探。
ROCm 的 LLVM 生态(开源公路):AMD 没有从头自研编译器,而是直接拥抱了工业标准的开源编译器框架 LLVM。AMD 开发了 HIP(可移植异构接口) 技术,作为代码的桥接层。
AMD 的战略很明确:通过 HIP 提供一个“一键翻译工具(hipify)”,试图让开发者把现有的 CUDA 代码自动翻译成 HIP 代码,从而实现“一次编写,到处运行”。
然而,在过去几年中,ROCm 的市场份额依然极低。其原因不在于硬件参数,而在于迁移成本的不可承受之重。早期的 ROCm 充满了编译 Bug、文档缺失、且由于缺乏类似英伟达的群众基础,企业为了将 CUDA 迁移到 ROCm,需要雇佣极其昂贵的系统级工程师进行手动调优,排查诡异的编译器错误。在分秒必争的 AI 竞赛中,没有公司愿意承担这种时间成本。
直到生成式 AI 的爆发,彻底改变了博弈的底层规则。
三、 悖论:AI 正在摧毁毁 CUDA 的围墙?
英伟达引以为傲的 AI 技术,正在成为其软件护城河最致命的“特洛伊木马”。这种蚕食主要通过两个路径发生:
1. 自动重写:生成式 AI 抹平了代码迁移成本
过去需要一个顶级专家团队耗时数月才能完成的“CUDA 到 ROCm/HIP”的代码重写与调优工作,现在正在被大语言模型(如 Claude 3.5、GPT-4o)以分钟级的时间彻底抹平。
现代 AI 编程大模型对底层的抽象语法树(AST)和 GPU 显存对齐有着完美的理解。AI 能够轻松识别 CUDA 代码中的专有算子,不仅能进行语法替换,还能根据 AMD 的硬件特性自动重写出高度优化、无 Bug 的 HIP 算子。
这构成了科技史上最讽刺的商业闭环:
英伟达售卖昂贵芯片 ➔ 科技巨头购买并训练出强大的生成式 AI ➔ 巨头用这个 AI 自动将 CUDA 代码重写迁移为 ROCm ➔ 巨头大规模转向采购便宜的 AMD 芯片 ➔ 摆脱英伟达
2. 降维打击:大一统中间件(Triton)的崛起
比 AI 自动写代码更致命的,是 AI 底层基础设施本身的架构演进——以 OpenAI 主导的 Triton 语言为代表的中间件迅速崛起。
在过去,深度学习框架(如 PyTorch)的底层需要针对英伟达编写大量的 CUDA 算子。而 OpenAI 发布的 Triton,是一种极简的、基于 Python 的开源编译器。它的目标是让普通程序员写出 Python 级别的简易代码,由 Triton 编译器自动去处理底层的并行和内存管理。
最关键的是:Triton 在设计之初,就同时开发了 NVIDIA 和 AMD 的双后端。
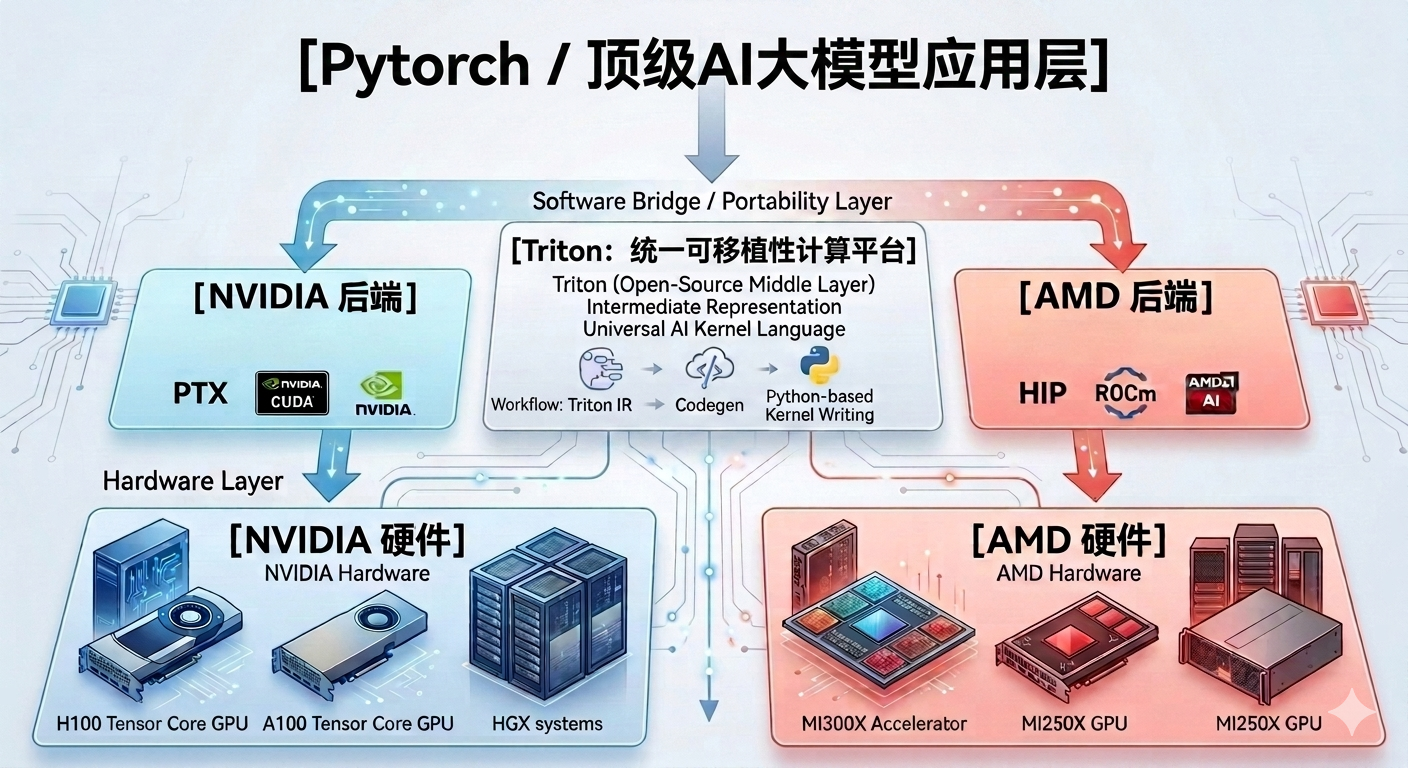
当 OpenAI、Meta 等大模型厂商逐渐将自家的核心模型从直接调用 CUDA 转向通过 Triton 编写时,底层的硬件开始变得完全透明和可替换。英伟达精心构筑的 CUDA 软件墙,正在被 Triton 这种中间件从内部逐步“瓦解”。
四、 反击:英伟达的防御与应对措施
面对软件护城河被 AI 和开源生态反向侵蚀的危机,英伟达的竞争策略已经发生了重大位移,他们正在将防御阵线从“单卡软件”推向更难被攻破的物理极限。
1. 从“卖芯片”彻底转变为“卖数据中心系统”
当单卡的软件壁垒逐渐被抹平时,英伟达开始在超大规模集群的网络互联上加高壁垒。
大模型训练现在已经进入万卡、十万卡时代,芯片之间的通信延迟比单卡算力更重要。
英伟达通过私有的 NVLink 协议、NVSwitch 芯片以及收购 Mellanox 获得的 InfiniBand(IB)网络技术,将上万张显卡织成一整个极其高效的“超级大脑”。这种万卡级别的物理网络拓扑、高频通信软硬件的极限整合,是单靠大模型“重写几行代码”绝对无法跨越的物理硬实力。
2. 恐怖的“摩尔定律”速度压制(时间窗口战)
英伟达正在采用商业史上罕见的高强度研发节奏,将硬件迭代速度提升至一年一代(从 Hopper 到 Blackwell,再到 Rubin 架构)。
即使 AI 能完美、零成本地将 CUDA 代码迁移到 AMD 的硬件上,如果英伟达新一代硬件的绝对性能依然能拉开对手一代以上的差距,那么理性的企业为了抢夺模型上线的关键时间窗口(Time-to-Market),依然不得不乖乖向英伟达奉上高额的溢价。
五、 展望:双雄逐鹿的终局走向
随着软件壁垒的消融,AI 芯片竞争的下半场,正在从过去的“生态垄断战”逐步回归到最纯粹的“硬件性价比、功耗比以及大规模网络互联能力”的物理对决。
英伟达(NVIDIA):向系统级平台与云计算巨头演进
英伟达的短期地位依然难以撼动。虽然单卡 CUDA 的壁垒在降低,但它凭借全栈的数据中心网络(NVLink)和一年一代的恐怖迭代速度,依然会牢牢占据最顶尖、最追求极致性能的超大规模 AI 训练市场(AI Training)。英伟达未来的角色将更像是一个“AI 基础设施的超级总承包商”。
AMD:在推理(Inference)与企业级市场迎来历史性爆发
对于 AMD 而言,这是历史上最好的红利期。随着全球大模型逐渐从“训练阶段”走向“大规模商业落地推理阶段”,市场对算力的需求正在从“不计成本追求极限性能”转向“追求极致的每美元性价比和功耗比”。
在 PyTorch、Triton 的加持以及 AI 自动迁移工具的普及下,ROCm 的软件劣势正在被快速拉平。AMD 的 Instinct 系列芯片凭借更大的显存容量和高性价比,将极大程度地蚕食云巨头、传统企业级私有化部署的推理算力市场。
总结:AI 没有毁灭英伟达,但 AI 会解放硬件市场
这场由英伟达亲手点燃的 AI 圣火,在不久的将来,会解除在其他硬件厂商身上的 CUDA 枷锁,让整个芯片行业重新回到了以物理性能与创新效率为核心的良性竞争赛道上。这算不算一个美好的愿望?!(Doggy)
